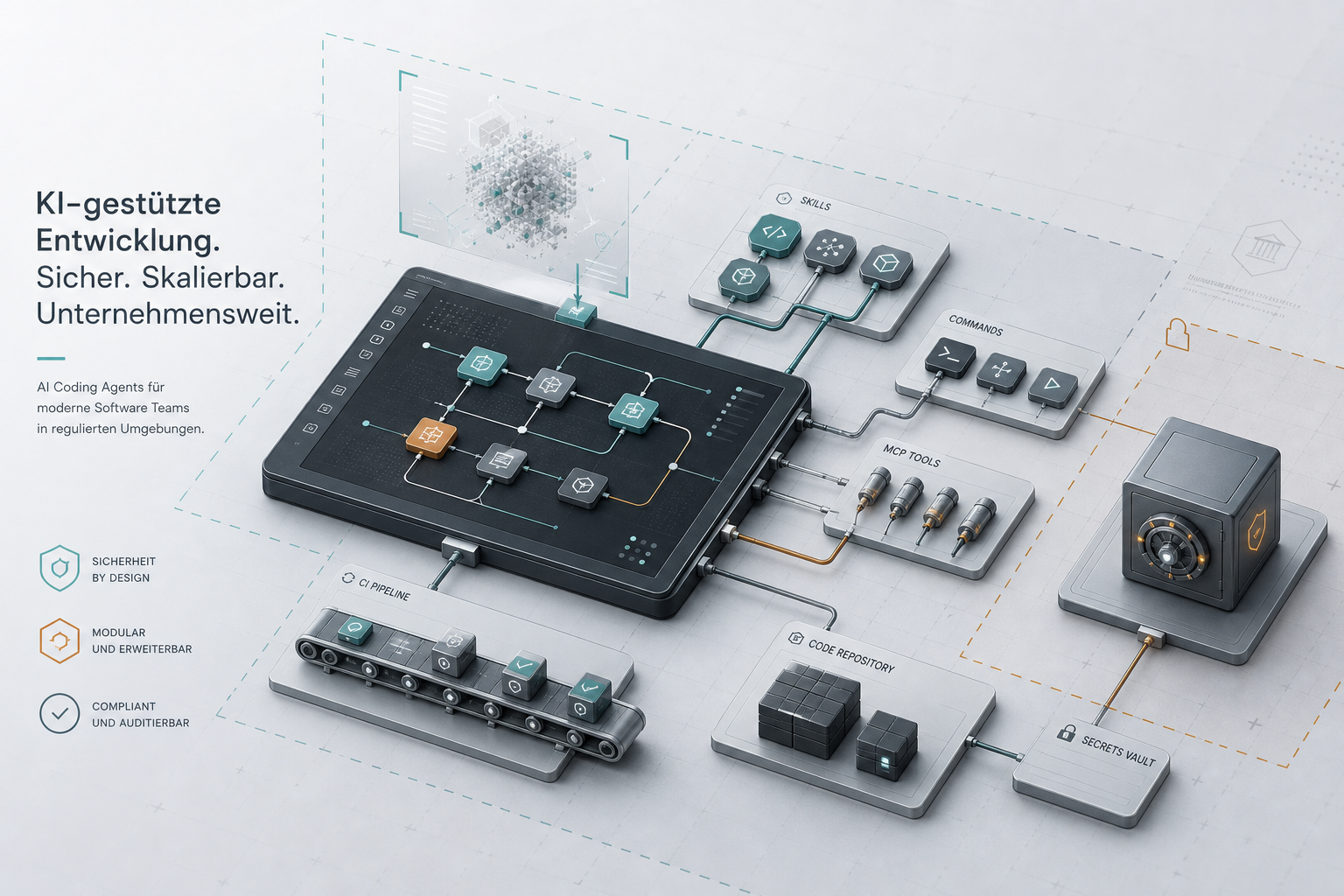
Wenn KI-Agenten Pakete installieren, wird Supply Chain Security zur Architekturfrage
KI-Coding-Tools beschleunigen Entwicklung. Sie beschleunigen aber auch den Moment, in dem kompromittierte Abhängigkeiten, Skripte und Zugangsdaten zu einem Produktionsrisiko werden.
Kyluke McDougall
Software-Architekt & Gründer

Die aktuelle Diskussion auf X rund um kompromittierte npm- und PyPI-Pakete ist für Produktteams interessanter, als es auf den ersten Blick wirkt.
Natürlich ist Software Supply Chain Security kein neues Thema. Kompromittierte Pakete, gestohlene Tokens, missbrauchte CI/CD-Pipelines und bösartige Installationsskripte gehören seit Jahren zu den Risiken moderner Softwareentwicklung. Wer mit JavaScript, Python, mobilen Apps oder Cloud-Infrastruktur arbeitet, lebt längst in einem Ökosystem aus tausenden indirekten Abhängigkeiten.
Neu ist die Geschwindigkeit, mit der KI-gestützte Entwicklungsumgebungen diese Risiken auslösen können.
In den letzten Stunden wurde auf X viel über den Mini-Shai-Hulud- beziehungsweise TanStack-Vorfall gesprochen: kompromittierte Pakete, OpenAIs öffentliche Reaktion, rotierte Code-Signing-Zertifikate, betroffene Entwicklergeräte, weitere Pakete im npm- und PyPI-Ökosystem und die Frage, wie automatisierte Entwicklungsabläufe solche Angriffe verstärken können. Besonders relevant ist dabei nicht nur der konkrete Vorfall, sondern die Rolle von KI-Coding-Tools, IDE-Helfern und Agenten, die Pakete installieren, Skripte ausführen, Dateien ändern und manchmal mit sehr weitreichenden Rechten arbeiten.
Das ist der Punkt, den Gründer, CTOs und Product Owner ernst nehmen sollten.
Wenn ein Mensch ein Paket installiert, ist das ein Dependency-Risiko. Wenn ein Agent ein Paket installiert, Skripte ausführt, Änderungen committet und Zugriff auf lokale Secrets oder CI-Kontext hat, wird daraus ein Ausführungs- und Governance-Risiko.
Der Paketmanager ist nicht mehr nur ein Werkzeug für Entwickler
Früher war der Ablauf meistens sichtbar genug, um ihn als Entwicklerhandlung zu behandeln.
Jemand öffnet ein Terminal. Jemand führt npm install, pnpm add oder pip install aus. Jemand sieht die Änderung in package.json, requirements.txt oder im Lockfile. Jemand committet die Änderung. In guten Teams läuft danach ein Review, ein Software-Composition-Analysis-Check, ein CI-Build und vielleicht noch ein Security-Scan.
Das war nie perfekt. Aber es hatte Reibung.
KI-gestützte Workflows reduzieren genau diese Reibung. Ein Agent kann erkennen, dass ein Paket fehlt. Er kann den Installationsbefehl vorschlagen oder direkt ausführen. Er kann die Importfehler beheben, Dateien anpassen, Tests starten und einen Pull Request vorbereiten. In lokalen IDEs, Coding-Agent-CLIs und internen Automatisierungen ist das sehr praktisch. Es spart Kontextwechsel und macht Entwicklung schneller.
Aber dieselbe Beschleunigung verändert den Risikopfad.
Ein kompromittiertes Paket muss nicht mehr auf einen müden Entwickler warten, der am Ende des Tages einen Befehl kopiert. Es kann in einen Workflow geraten, in dem ein Agent die passende Abhängigkeit sucht, installiert, ein Lifecycle-Skript auslöst und danach weiterarbeitet, als wäre nichts Besonderes passiert. Wenn dieser Workflow Zugriff auf .env-Dateien, npm-Tokens, GitHub-Tokens, Cloud-Credentials, SSH-Keys oder CI-Variablen hat, ist die Grenze zwischen “Abhängigkeit installiert” und “Umgebung kompromittiert” sehr dünn.
Das ist keine Panikmache. Es ist normale Architekturarbeit.
Ein System, das Code aus dem Internet lädt und ausführt, braucht klare Grenzen. KI ändert daran nichts. KI sorgt nur dafür, dass dieses System häufiger, schneller und an mehr Stellen aktiv wird.
Die eigentliche Frage lautet: Wer darf ausführen?
Viele Diskussionen über KI-Coding-Tools konzentrieren sich auf Codequalität.
Schreibt der Agent guten Code? Versteht er die Architektur? Findet er Bugs? Kann er Tests reparieren? Das sind wichtige Fragen. Für ernsthafte Produkte reichen sie aber nicht.
Die operative Frage lautet: Was darf der Agent tun?
Darf er Pakete installieren? Darf er Lifecycle-Skripte ausführen? Darf er Shell-Befehle starten? Darf er auf lokale Umgebungsvariablen zugreifen? Darf er Dateien außerhalb des Repositories lesen? Darf er Git-Konfiguration, Hooks oder IDE-Settings ändern? Darf er mit einem Token arbeiten, der auch Releases, Paketveröffentlichungen oder Cloud-Ressourcen steuern kann?
Sobald die Antwort irgendwo “ja” lautet, ist der Agent nicht mehr nur ein Chatfenster. Er ist ein Akteur in der Software-Lieferkette.
Das ist der richtige mentale Wechsel: KI-Coding-Agenten sind nicht nur Produktivitätswerkzeuge. In produktionsnahen Umgebungen sind sie Ausführungsumgebungen mit Berechtigungen.
Das muss nicht gegen den Einsatz von KI sprechen. Im Gegenteil: Teams, die das sauber modellieren, können KI sehr viel zuverlässiger nutzen als Teams, die einfach hoffen, dass schon nichts Schlimmes passiert.
Dependency-Änderungen brauchen einen eigenen Pfad
Ein praktischer Schritt ist erstaunlich simpel: Dependency-Änderungen sollten nicht nebenbei in Feature-Änderungen verschwinden.
Wenn ein KI-Agent einen Button baut, einen API-Endpunkt erweitert und gleichzeitig drei neue Pakete installiert, ist der Review schwer. Der Reviewer schaut auf Produktlogik, UI-Verhalten, Typfehler, Tests, vielleicht Performance. Die neue Abhängigkeit ist nur eine Zeile in einem Lockfile mit hunderten Änderungen.
Genau dort verstecken sich Risiken.
Für ernsthafte Produkte ist es sinnvoll, Dependency-Änderungen bewusster zu behandeln:
- neue Laufzeitabhängigkeiten getrennt reviewen;
- Lockfile-Änderungen nicht blind akzeptieren;
- bekannte Paketquellen und interne Policies definieren;
- install scripts und postinstall-Verhalten prüfen;
- veraltete, typosquatted oder ungewöhnlich neue Pakete markieren;
- CI so konfigurieren, dass Dependency-Scans blockieren können;
- den Agenten anweisen, vorhandene Standardbibliotheken und bereits freigegebene Pakete zu bevorzugen.
Das klingt weniger aufregend als “vollautonome Entwicklung”. Es ist aber genau die Art von Prozess, die autonome oder halbautonome Entwicklung überhaupt erst tragfähig macht.
McDougall Digital achtet bei AI-unterstützter Lieferung deshalb nicht nur darauf, ob ein Tool Code erzeugt. Entscheidend ist, ob die entstehende Lieferkette erklärbar bleibt: Welche Abhängigkeiten kommen hinein, welche Befehle werden ausgeführt, welche Secrets sind erreichbar, welche Gates stehen vor Produktion?
Secrets gehören nicht in die Reichweite jedes Entwicklungshelfers
Der kritischste Teil vieler Supply-Chain-Vorfälle ist nicht der Code selbst. Es sind die Zugangsdaten, die der Code erreichen kann.
Ein kompromittiertes Paket, das in einer leeren Sandbox läuft, ist unangenehm. Ein kompromittiertes Paket, das auf einem Entwicklergerät mit produktionsnahen Tokens, privaten Repositories, Cloud-Zugängen, npm-Veröffentlichungsrechten oder Code-Signing-Material läuft, ist eine andere Kategorie.
KI-Agenten verschärfen diese Frage, weil sie häufig in denselben Umgebungen laufen wie Entwickler:
- lokale Repositories;
- IDE-Konfiguration;
- Terminalzugriff;
.env-Dateien;- SSH-Agent;
- Git-Credentials;
- API-Tokens für interne Tools;
- Zugriff auf Issue Tracker, CI oder Deployment-Systeme.
Wenn ein Agent dort Paketmanager-Befehle ausführen darf, muss das Sicherheitsmodell diese Realität abbilden.
Ein guter Zielzustand ist nicht “niemand darf mehr etwas installieren”. Das wäre für Produktentwicklung unbrauchbar. Ein guter Zielzustand ist: Installationen passieren in kontrollierten Kontexten, mit minimalen Rechten, sichtbaren Logs und klaren Review-Gates.
Für viele Teams bedeutet das:
- Entwicklungs-Secrets von Produktions-Secrets trennen;
- kurzlebige Tokens statt dauerhafter persönlicher Tokens nutzen;
- Signing Keys und Publishing-Rechte nicht auf normalen Entwicklungsmaschinen lagern;
- Agenten in Containern, Dev-Environments oder eingeschränkten Workspaces laufen lassen;
- CI-Jobs mit minimalen Berechtigungen ausstatten;
- gefährliche Befehle explizit bestätigen lassen;
- nach Dependency-Vorfällen Token-Rotation und Lockfile-Prüfung als Standardablauf haben.
Das ist nicht nur Security. Es ist Betriebsfähigkeit.
Ein Team, das weiß, welche Berechtigungen wo liegen, kann nach einem Vorfall schnell reagieren. Ein Team, das alles in lokalen Maschinen, alten Tokens und impliziten Tool-Rechten versteckt hat, muss erst seine eigene Lieferkette rekonstruieren.
KI braucht dieselben Gates wie Menschen, oft sogar klarere
Ein häufiger Fehler ist, KI-generierte Änderungen als Sonderfall zu behandeln.
Ein Entwickler würde keinen unreviewten Code direkt in Produktion schieben. Ein Agent sollte das auch nicht tun. Ein Entwickler sollte nicht heimlich neue kritische Abhängigkeiten einführen. Ein Agent auch nicht. Ein Entwickler sollte keine Credentials in Logs, Backups oder temporären Dateien hinterlassen. Ein Agent auch nicht.
Der Unterschied ist: Bei Menschen verlassen sich Teams oft auf Gewohnheit, Erfahrung und implizites Urteil. Bei Agenten funktioniert das schlechter. Deshalb müssen die Gates expliziter werden.
Gute KI-Lieferprozesse haben klare Regeln:
- Welche Repositories darf der Agent sehen?
- Welche Aufgaben darf er ohne Bestätigung ausführen?
- Welche Befehle sind blockiert?
- Welche Dateien sind tabu?
- Wann muss ein Mensch reviewen?
- Welche Tests müssen laufen?
- Welche Security Checks sind verpflichtend?
- Wie wird dokumentiert, welche Änderungen vom Agenten stammen?
Diese Regeln müssen nicht bürokratisch sein. Sie sollten nah am echten Risiko liegen. Ein interner Prototyp braucht andere Gates als eine Zahlungsfunktion, ein medizinischer Workflow, ein Kundenportal oder ein System mit personenbezogenen Daten.
Der Fehler wäre, gar keine Unterscheidung zu machen.
Für Produktteams ist das eine Architekturentscheidung
Supply Chain Security klingt oft nach einem Thema für Security-Teams. Für moderne Produktteams ist es breiter.
Es betrifft Architektur, weil Abhängigkeiten die Struktur und Wartbarkeit eines Systems beeinflussen.
Es betrifft Produktmanagement, weil neue Features manchmal durch schnelle Paketentscheidungen beschleunigt werden, die später hohe Kosten erzeugen.
Es betrifft Operations, weil Vorfälle nur dann sauber beherrschbar sind, wenn Logs, Zuständigkeiten, Rollback-Pfade und Token-Rotation vorbereitet sind.
Es betrifft Compliance, weil deutsche und europäische Kunden zunehmend wissen wollen, wie Software geliefert, geprüft und abgesichert wird.
Und es betrifft AI-Adoption, weil KI-Tools nur dann dauerhaft helfen, wenn ihre Geschwindigkeit nicht in unsichtbarem Risiko endet.
Die gute Nachricht: Man muss dafür nicht sofort eine riesige Plattform bauen. Viele sinnvolle Maßnahmen sind pragmatisch:
- eine kurze Policy für KI-Agenten im Repository;
- klare Regeln für Dependency-Änderungen;
- getrennte Entwicklungs-, Test- und Produktionskontexte;
- SCA- und Secret-Scanning in CI;
- eingeschränkte Tokens für lokale Tools;
- Review-Checklisten für agentische Änderungen;
- regelmäßige Updates und ein sauberer Incident-Ablauf;
- ein Architekturreview für kritische Workflows, bevor sie wachsen.
Das Ziel ist nicht, Entwicklung langsam zu machen. Das Ziel ist, Geschwindigkeit kontrollierbar zu machen.
Wo McDougall Digital helfen kann
Für viele Teams ist der schwierigste Teil nicht das Wissen, dass Risiken existieren. Es ist die Übersetzung in einen vernünftigen Lieferprozess, der zum Produkt passt.
Ein junges SaaS-Produkt braucht andere Kontrollen als ein Mittelstands-internes Tool. Ein Kundenportal mit personenbezogenen Daten braucht andere Grenzen als ein Marketing-Prototyp. Ein Team mit erfahrenen Entwicklern braucht andere Agentenregeln als ein Gründerteam, das stark auf Replit, Cursor, Claude Code oder Codex setzt.
McDougall Digital hilft genau an dieser Schnittstelle: AI-unterstützte Entwicklung so aufzusetzen, dass Architektur, Produkturteil, Security und Betrieb zusammenpassen.
Praktisch kann das bedeuten:
- bestehende Repositories auf Agenten- und Dependency-Risiken prüfen;
- CI/CD, Secrets und Paket-Workflows härten;
- KI-Coding-Workflows mit sinnvollen Berechtigungen und Review-Gates entwerfen;
- AI-gebaute Prototypen produktionsreif strukturieren;
- interne Tools so bauen, dass sie schnell entstehen, aber nicht unkontrolliert wachsen;
- Teams eine klare, pragmatische Operating Model für KI-unterstützte Softwareentwicklung geben.
Der Mini-Shai-Hulud- und TanStack-Moment wird wieder aus der Timeline verschwinden. Die Lehre bleibt.
Wenn KI-Agenten Software bauen, sind sie Teil der Lieferkette. Und eine Lieferkette, die schneller wird, braucht nicht weniger Architektur. Sie braucht bessere Grenzen.